
0
widoki


Ostatnia aktualizacja

Wayback Machine jest najpopularniejszą częścią Witryna internetowa archiwum internetowego. Bezpłatne narzędzie online, wprowadzone po raz pierwszy w 2001 r., Umożliwia cofnięcie się w czasie i sprawdzenie, jak w określonych momentach wyglądały strony internetowe na całym świecie. W Wayback Machine znajduje się 562 miliard stron internetowych w czasie pisania tego tekstu, a każdego roku jest o wiele więcej dodawanych.
Oto spojrzenie na Wayback Machine i co sprawia, że jest wyjątkowy.
Internet Archive, utworzone przez Brewstera Kahle i Bruce'a Gilliata, jest organizacją non-profit, której misją jest „powszechny dostęp do wszelkiej wiedzy”. Od początku, organizacja zapewniła bezpłatny publiczny dostęp do zdigitalizowanych materiałów, takich jak strony internetowe, książki, nagrania audio, w tym koncerty na żywo, filmy, obrazy i oprogramowanie programy.
Do tej pory wszystko zgromadzone przez Internet Archive zajmuje ponad 70
Tylko jedna część Internet Archive, Wayback Machine, została zaprojektowana do przechwytywania zmienionej lub usuniętej zawartości witryn internetowych. Od momentu uruchomienia stało się jednym z najpopularniejszych i najbardziej rozpoznawalnych miejsc w sieci. Kahle i Gilliat nazwali witrynę na cześć fikcyjnego urządzenia podróżującego w czasie z serialu animowanego z lat 60. XX wieku, The Rocky and Bullwinkle Show.
Chociaż Internet Archive udostępnił witrynę publicznie dopiero w październiku 2001 r., Wayback Machine zaczął archiwizować buforowane strony internetowe od maja 1996 r. Do 2001 roku na taśmach cyfrowych przechowywano informacje, które były dostępne tylko dla wybranych naukowców i badaczy. Kiedy wszystko weszło do publicznej wiadomości pięć lat później (jak długo planowano), zawierało już ponad 10 miliardów zarchiwizowanych stron.
Obecnie witryna przechowuje historyczne dane internetowe w klastrze węzłów systemu Linux. Wayback Machine pobiera wszystkie publicznie dostępne informacje i pliki danych ze stron internetowych za pośrednictwem swojego mechanizmu indeksowania. Jednak nie wszystko, co jest publikowane w witrynie, jest tutaj uwzględnione, ponieważ niektóre treści są ograniczone lub przechowywane w bazach danych, które nie są dostępne. Z tego powodu niektóre witryny internetowe są indeksowane lepiej niż inne, w zależności od tego, w jaki sposób programiści tworzyli witrynę w danym momencie.
Zauważysz też, że im nowsze archiwum, tym więcej treści jest dostępnych dla danej witryny. Nowe narzędzie, które zostało wprowadzone przez Internet Archive w 2005 roku, jest jednym z powodów, dla których nowsze dane są bardziej kompletne. Archive-It.org pomaga przezwyciężyć niespójności w witrynach internetowych częściowo zapisanych w pamięci podręcznej, umożliwiając instytucjom i twórcom treści gromadzenie i przechowywanie zbiorów treści cyfrowych.
Roboty sieciowe, czasami nazywane pająkami lub robotami pająkowymi, są tak stare, jak sam Internet. Te roboty to boty internetowe, które nieustannie przeglądają sieć w celach indeksowania, co czyni je ważnym elementem każdej nowoczesnej wyszukiwarki. Przeszukiwacze używane przez Wayback Machine do tworzenia cyfrowych migawek stron internetowych pochodzą z różnych źródeł, które z czasem ulegały zmianom.
Jak szybko zauważysz, częstotliwość wykonywania zrzutów różni się znacznie w zależności od witryny. Zwykle im większa (i być może bardziej popularna) witryna internetowa, tym częściej występuje indeksowanie. Ponadto wiele zależy od tego, jak często witryna ma zmiany na stronie. Ostatecznie indeksowane są nawet najmniejsze witryny internetowe, chyba że istnieje powód, dla którego tak się nie dzieje. Na przykład witryny chronione hasłem nie są indeksowane, podobnie jak witryny, których właściciele zażądali ich nieuwzględniania.
Witryna internetowa Wayback Machine jest łatwa w użyciu dla każdego. Aby znaleźć historyczne migawki serwisu WWW, wpisz jego nazwę w wyszukiwarce serwisu. Na stronie wyników wyszukiwania hiperłącza oznaczają daty i godziny archiwizacji witryny. Kliknij link, aby zobaczyć witrynę „z powrotem w czasie”.
W poniższych przykładach można zobaczyć pierwszą stronę witryny Apple nagraną w lutym 2005 i listopadzie 2014 oraz stronę główną CNN z marca 2004 i września 2010.
Uwaga: te indeksowania obejmują również linki do innych stron zarejestrowanych w określonych dniach, a nie tylko do stron głównych.
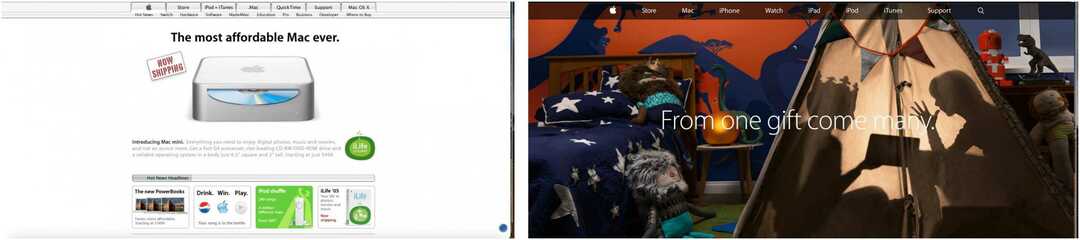
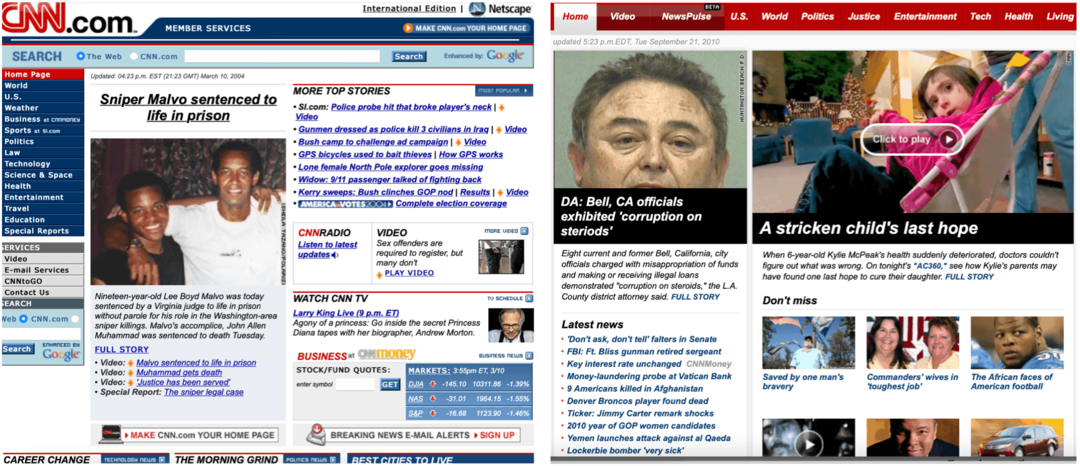
Stworzony zarówno dla naukowców, jak i opinii publicznej, Wayback Machine ma kilka wbudowanych narzędzi, których zwykli użytkownicy mogą przegapić. Na przykład z założenia strony wyników wyszukiwania są łatwe do odniesienia. Jak wyjaśniono: „Jeśli znajdziesz zarchiwizowaną stronę, do której chciałbyś się odwołać na swojej stronie internetowej lub w artykule, możesz skopiować adres URL. Możesz nawet użyć rozmytego dopasowania adresu URL i określenia daty… ale to trochę bardziej zaawansowane ”.
Wayback Machine umożliwia również właścicielom witryn użycie funkcji „Zapisz teraz stronę”, aby zapisać określoną stronę. A jednak nie jest doskonały. Obecnie ta funkcja nie dodaje adresu URL witryny do żadnych przyszłych indeksowań. Ponadto żądanie nie zapisuje więcej niż jednej strony. Jest to jednak dobry pierwszy krok, aby zarchiwizować stronę główną swojej witryny w celach archiwalnych.
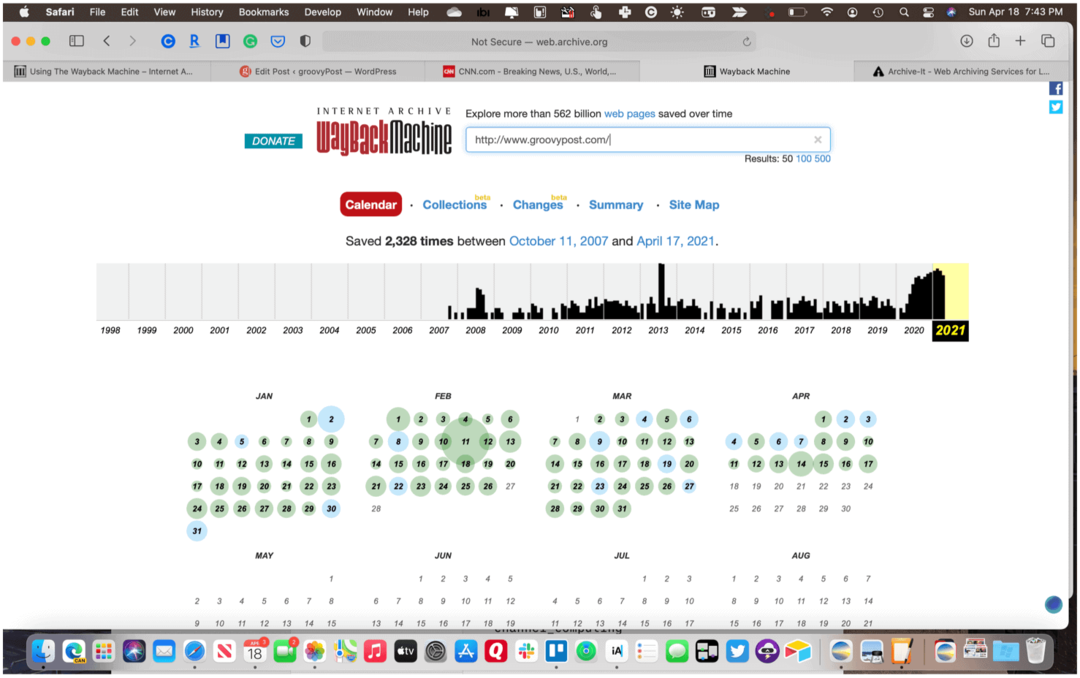
Nie musisz za każdym razem odwiedzać Wayback Machine, aby przeprowadzić nowe wyszukiwanie. Zamiast tego możesz znaleźć zawartość, wpisując adres na pasku narzędzi przeglądarki internetowej. Użyj tego formatu do wszystkich wyszukiwań: http://web.archive.org/*/www.yoursite.com/*. Na przykład użyj http://web.archive.org/*/www.groovypost.com/* aby znaleźć zarchiwizowane strony dla GroovyPost!
Wreszcie, Wayback Machine nie znajduje się tylko w sieci. Możesz znaleźć aplikację Wayback Machine dla iOS i Android. Istnieją również rozszerzenia dla Chrome, Safari i Firefox. Programiści będą również chcieli sprawdzić interfejsy API Internet Archive Wayback Machine. Ułatwiają one programistom pobieranie informacji o danych przechwytywania Wayback.
Internet Archive Wayback Machine obsługuje kilka różnych interfejsów API. W ten sposób ułatwia programistom pobieranie informacji o danych przechwytywania Wayback.
Cofanie się w czasie do ulubionych witryn internetowych to główny powód, dla którego warto odwiedzić Wayback Machine. Jest to również doskonałe narzędzie dla każdego, kto szuka historii witryny pod kątem projektów szkolnych lub zastosowań biznesowych. Cokolwiek robisz, odwiedź Wayback Machine i zobacz, co możesz odkryć w kilku prostych krokach.
Aby uzyskać więcej informacji na temat usługi subskrypcji archiwum internetowego Archive-It, odwiedź witrynę oficjalna strona internetowa i zacznij współtworzyć już dziś!

