128
widoki

Ostatnia aktualizacja dnia

Przekształcenie „dużych zbiorów danych” w sensowne wyniki może wydawać się skomplikowane. Ale kiedy zrozumiesz, co to jest i jak to działa, nadanie temu sensowi nie jest tak skomplikowane.
Przez lata wiele modnych słów stało się modnych w wielu branżach. Niewiele jest tak popularnych i tak długo, jak duże zbiory danych. Ale czym właściwie są duże zbiory danych?
Big data odnosi się do wirtualnego oceanu informacji z różnych źródeł, analizowanych i filtrowanych w taki sposób, aby uzyskać sensowne i przydatne wyniki.
Proces przekształcania „dużych zbiorów danych” w sensowne wyniki może wydawać się skomplikowany i trudny. Jednak gdy zrozumiesz, co to jest big data i jak to działa, zrozumienie, jak nadać temu sensowi, nie wydaje się takie skomplikowane.
Kiedy słyszysz, jak ludzie mówią o „dużych danych”, zwykle jest to z dużą ilością machania ręką i dużymi słowami. Ale kiedy sprowadzasz całą hiperbolę, faktyczne „dane” to tak naprawdę wiele strumieni danych wejściowych.
Aby to zrozumieć, przykład może pomóc. Załóżmy, że prowadzisz firmę produkującą parasole. Twój dział marketingu szuka sposobu, aby lepiej przewidzieć, kiedy zapotrzebowanie rynku wzrośnie.
Przed dniami wielkich zbiorów danych marketerzy badali trendy rynkowe, wysyłali ankiety wśród klientów i wiele innych działań.

Gromadzą wszystkie te dane i przechowują je w wewnętrznych bazach danych własnej firmy. Ktoś może nawet odpowiadać za aktualizację danych z badań marketingowych co roku lub co kwartał.
Pojawienie się dużych zbiorów danych zwiększa jednak możliwości prowadzenia tego rodzaju badań. W szczególności duże zbiory danych są szczególnie skuteczne w identyfikowaniu ważnych trendów lub wydarzeń w czasie zbliżonym do rzeczywistego.
Dane wejściowe do tego rodzaju analizy „dużych danych” mogą obejmować strumienie danych w czasie rzeczywistym, pisząc kod, który podłącza się do Interfejs programowania aplikacji (API) wielu różnych firm, które upubliczniły te dane:
Aby korzystać z dużych zbiorów danych, zespół marketingowy tej firmy musiałby, w niektórych przypadkach, instalować nowe technologie.
Może to obejmować technologię Internetu przedmiotów (IoT) u detalistów, która śledzi zachowania konsumentów i informuje o nich. Może to również wymagać napisania przez programistę kodu wymaganego do połączenia z interfejsem API Twittera, aby odfiltrować wszelkie tweety zawierające „parasole” lub nazwę firmy.
Każda z tych technologii jest teraz dostępna dzięki Internetowi. Internet pozwala każdemu na dostęp do strumieni danych z całego świata.
Oto jak konfiguracja w naszym przykładzie może działać w tym przypadku.
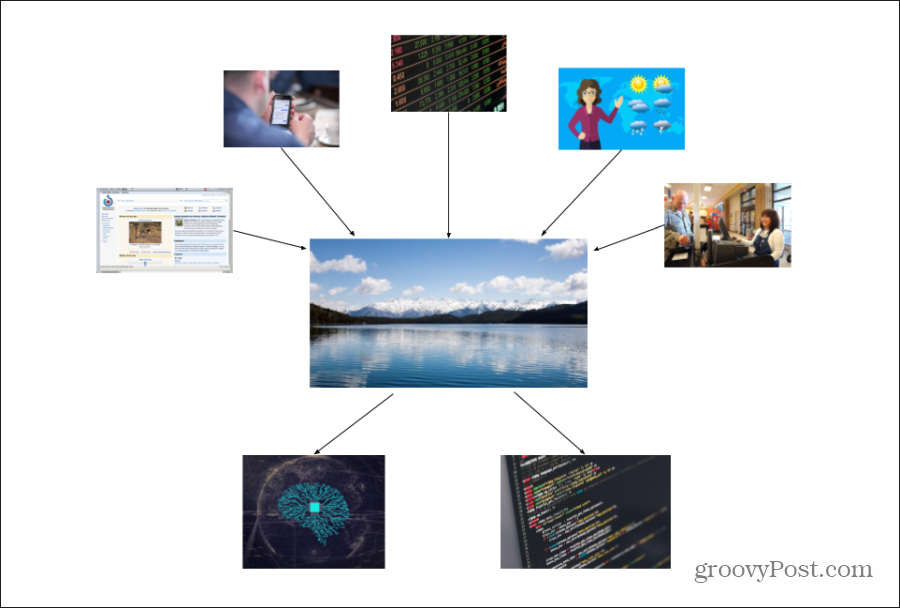
Ten schemat pokazuje, jak dane przepływają do „jeziora danych” firmy z wielu różnych źródeł. Przychodzące dane mogą mieć inną strukturę, ale ważne jest, aby zebrać jak najwięcej danych ze wszystkich źródeł.
W przeciwieństwie do bazy danych, która zawiera uporządkowane dane zorganizowane w określone kolumny i wiersze, jezioro danych jest ogromnym repozytorium dla wielu różnych form danych.
Przechowywane dane mogą być uporządkowane lub nieustrukturyzowane. Oznacza to, że może mieć uporządkowane wiersze i kolumny lub nie. Dane mogą być ciągami, które używają określonego formatowania do oddzielania danych. Każde źródło danych może przesyłać dane do jeziora danych w dowolnej formie.
Wyobraź sobie jezioro danych jak ogromną bibliotekę, która zawiera wiele form mediów, takich jak książki, obrazy na mikrofiszach i wideo na DVD.

Wyobraź sobie inżyniera cyfrowej inteligencji i analizy danych jako patronów tej biblioteki. Ci klienci mogą cyfrowo wyciągać dane z książek, mikrofisz i płyt DVD oraz znajdować sposoby mieszania i łączenia tych danych oraz uczenia się na podstawie ich korelacji.
Z tych odkryć pochodzi rzeczywista, praktyczna inteligencja. Niektóre z naszych przykładów mogą obejmować:
Wszystkie te wnioski mogą skłonić zespół ds. Marketingu do inwestowania w więcej reklam geograficznych, w których popyt na sprzedaż parasolową jest znacznie większy. Operacje produkcyjne mogłyby również przenieść wysiłki produkcyjne na te obszary świata, które są bliżej miejsc, w których sprzedaż prawdopodobnie wzrośnie.
W ten sposób, korzystając z dużych zbiorów danych, każda firma może usprawnić marketing i operacje.
Kolejne pytanie brzmi: w jaki sposób firmy przetwarzają tak duże ilości danych i identyfikują trendy?
Ten rodzaj kruszenia danych wymaga ogromnych zasobów komputerowych. Do tego stopnia, że firmy nie używają już dużych komputerów typu mainframe w pomieszczeniach, jak kiedyś. Wiele z tych usług jest teraz kupowanych w chmurze. Usługi analizy danych w chmurze, takie jak Apache Hadoop, oferują wiele węzłów komputerowych w dużej sieci chmurowej. Każdy z tych węzłów przyczynia się do mocy obliczeniowej wymaganej do analizy ogromnych strumieni danych z wielu źródeł.

Ten rodzaj mocy obliczeniowej jest sercem inteligencji maszynowej lub cyfrowej i analizy danych. Hadoop to platforma programowa, która sprawia, że cała sieć ogromnych mocy obliczeniowych działa zgodnie z wymaganiami inżynierów cyfrowej inteligencji.
Gdy silnik obliczeniowy generuje przydatne informacje, są one zazwyczaj dostarczane do firmy w postaci pulpitów nawigacyjnych lub raportów.
Prawda jest taka, że „duże zbiory danych” to coś więcej niż żargon korporacyjny. Wiele firm uczy się, że dzięki lepszemu wykorzystaniu danych są w stanie osiągnąć wiele osiągnięć.
Podczas gdy wiele z osiągnięć dużych zbiorów danych w ostatnich latach pozostaje praktycznie niewidocznych dla społeczeństwa, duże zbiory faktycznie miały znaczący wpływ na codzienne życie ludzi na całym świecie.